The 4 Key Challenges You’ll Face as Your Kafka Estate Grows

Apache Kafka is a distributed streaming technology that was developed at LinkedIn and open-sourced in 2011. Since then, Kafka has exploded in popularity and has been widely adopted by companies across all industries. With any technology, as it matures and is more widely adopted, it becomes harder to manage and Kafka is no exception.
From my experience working with customers and prospects interested in leveraging the power of real-time data distribution, Kafka’s popularity took off about 5-7 years ago and since then I have seen it adopted by many enterprises. As with most technology adoption cycles, smaller companies are quicker to adopt new technologies and push changes to production, whereas large enterprises require enterprise-grade features and take longer to go live. In the last 1-2 years, I have noticed that more and more companies who first adopted Kafka few years ago are starting to notice the complexities that come with increasing adoption. With any messaging technology, there are some side-effects to its increasing adoption by different lines-of-businesses and organizations looking to adopt event-driven architecture.
I’ll explain here the four key challenges organizations face as they deploy more Kafka across their enterprise. These challenges drove us to invent and bring to market a brand new kind of software, an “event portal,” called Solace Event Portal for Apache Kafka.
Kafka Challenge 1: Lack of Visibility
First of all, how do you document everything? Enterprise Kafka estates consist of multiple Kafka clusters, numerous topics, some consumer groups, and several schemas. In the initial days of adoption, this is not a concern. No one feels the need to document those 5 topics you might have on the first day your application goes live. However, increased adoption means tomorrow you might have 10x more topics, 5x more schemas, and maybe 3x more consumer groups. As more time passes, you eventually lose track of how many of these objects exist on your Kafka clusters. A large American bank I worked with thought they knew how many topics they had but when they dug deeper (by running Event Portal’s discovery scan), they found out they were off by several orders of magnitude. My colleague Jesse published a blog post about their experience that I suggest you read:
Why is that a big deal? Who cares if you discovered few more topics (or even a lot more topics) than you thought you had. They’re just files on your disk and storage is cheap. That’s true, but an organization should have better control over its data and topics contain data in their log files. An organization should know what data they have and how it is being used and they should proactively avoid having data duplicated. One of the reasons why an organization might have so many unknown topics is that developers created topics without authorization or review. No one kept track of these topics that were created, and they might very likely be duplicates of topics that already exist. This means that publishing of the data to these duplicate topics is being repeated, leading to inefficiency, additional storage cost, additional management overhead, and increased dependency on new topics. As an analogy, this is similar to how organizations have a master table which repeatedly gets duplicated by each and every team until no one knows who is consuming data from the master table.
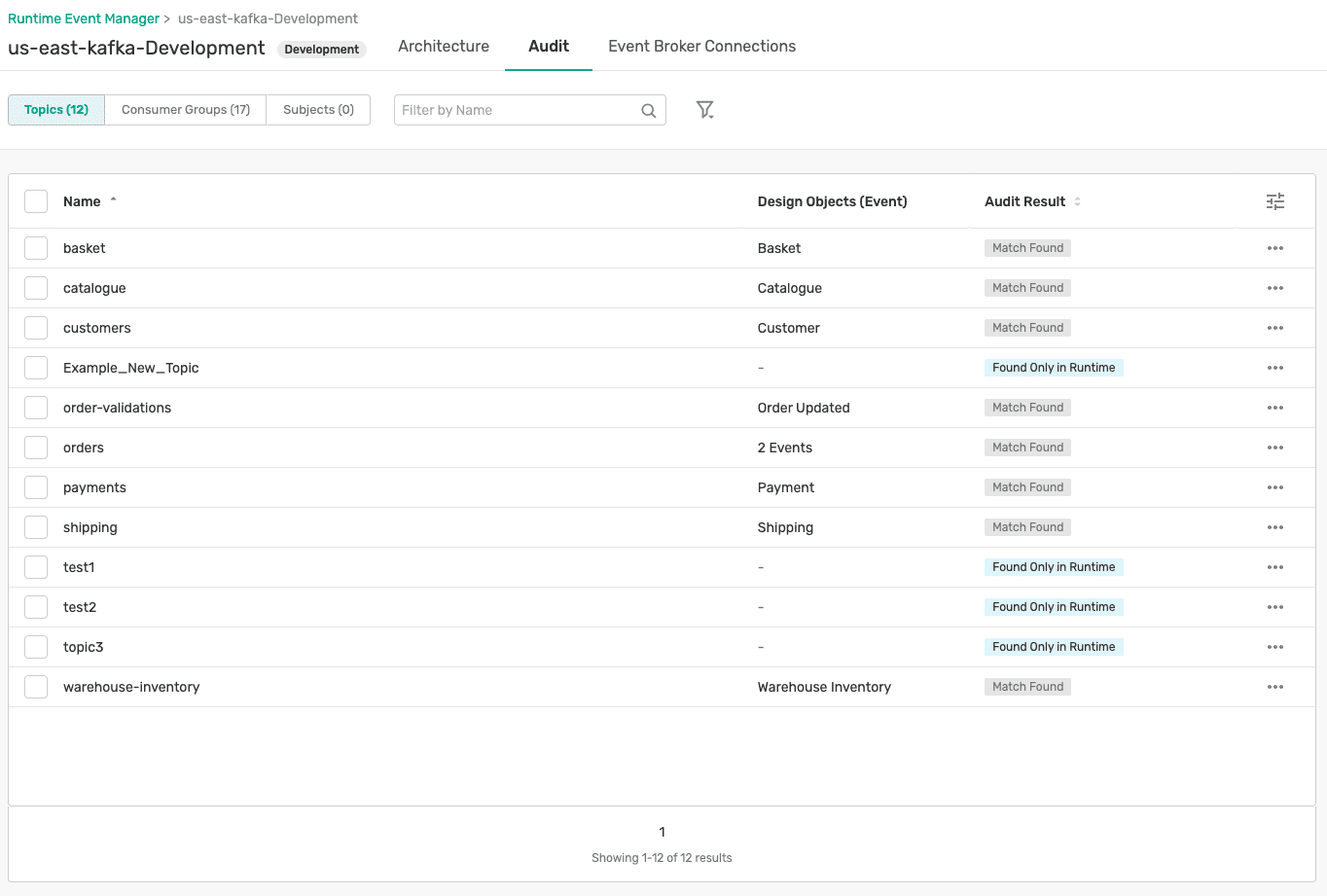
So, how do we fix that? Event Portal for Kafka addresses this challenge by allowing users to run a scan to discover all the important objects (topics, consumer groups, and schemas) across their Kafka clusters and document them. This gives you complete visibility into your Kafka estate. You are not blind anymore with respect to what’s happening with the investment you have made into Kafka. You are able to establish appropriate governance and eliminate duplication of existing topics which increases your topics’ and data’s reusability. Moreover, the objects that are discovered are stored in a catalog so your developers and architects can easily search across them and find what data is available to them. Afterall, what’s the point of collecting all this information and documenting it if you can expose and leverage it to be more efficient. All of this leads to increased productivity, higher efficiency, reduced duplication and associated infrastructure cost, and better governance.
Kafka Challenge 2: Lack of Relationships
While the first challenge focused on objects, such as topics and schemas, there is another dimension that is very important to document and that’s the relationships between them. While knowing how many topics, schemas, and consumer groups you have is important, it is also very important to how different applications interact with these objects. As companies increase their adoption of Kafka, it becomes increasingly challenging to keep track of how applications are leveraging topics and schemas. Here are some questions to ask yourself to find out if this is a challenge you are currently facing:
- Which applications are publishing and consuming what data?
- Which topics is the data being published to or being consumed from?
- What are the relevant schemas associated with the topics?
- Which consumer groups are consuming from which topics?
Why is it important to know this stuff? Because data is important to every company and knowing how data is being used is equally important. Mapping relationships between these objects allows you to discover key dependencies. For example, if a publishing application is publishing credit card transactions to a topics that is being consumed by 5 downstream applications such as fraud and validation then you need to know which applications will be impacted if you were to roll out a change to the topic that the publishing application is publishing credit card transactions to.
Event Portal for Kafka not only allows you to catalog your Kafka objects (as mentioned in previous section) but it also allows you to map important relationships between these objects and your applications. With this information, you have a complete picture of what’s happening in your Kafka cluster, allowing you to better manage and govern your Kafka estate.
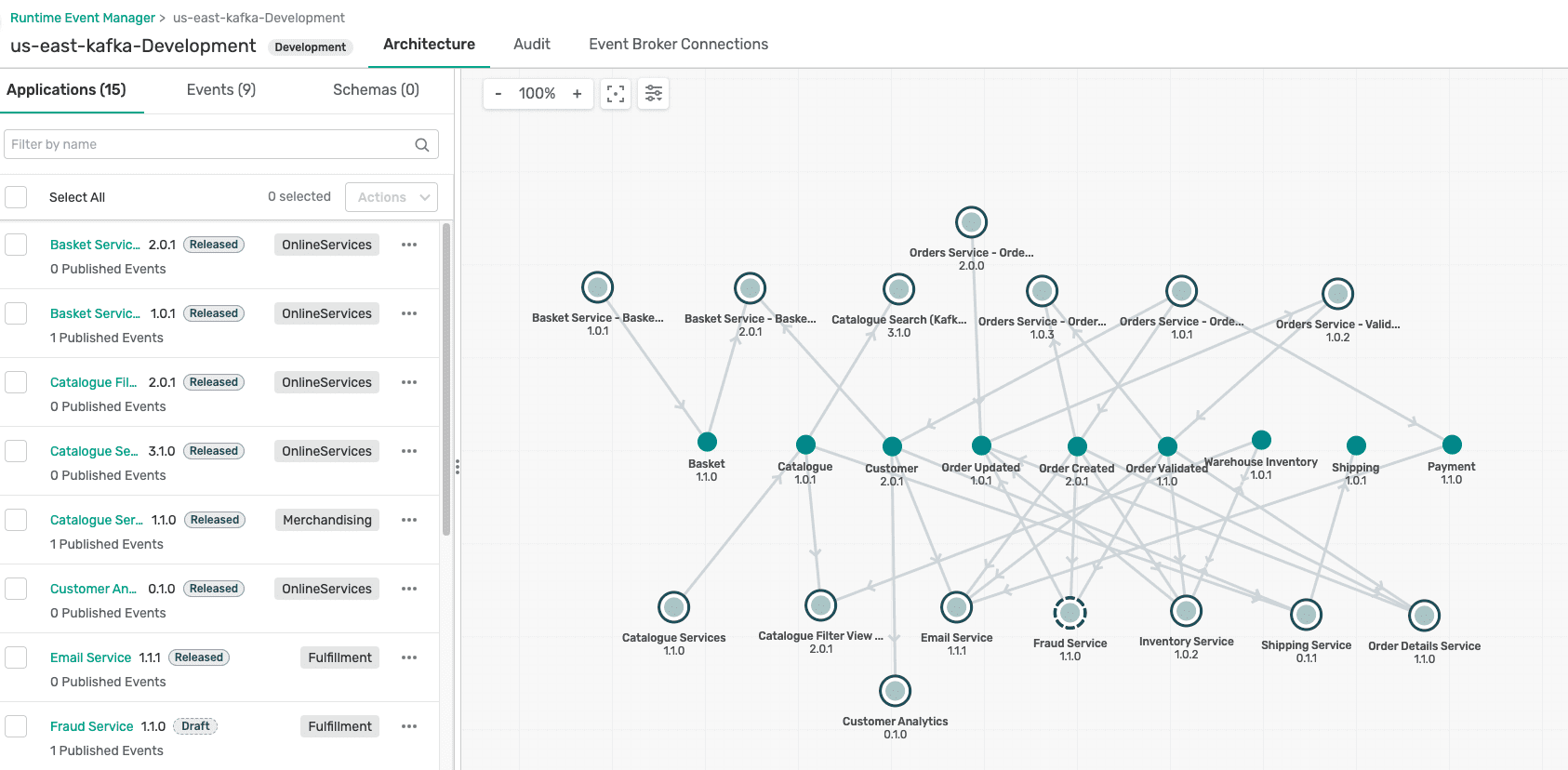
And how does your company benefit? The biggest benefit is fewer outages due to changes. You have more visibility into key dependencies, and you can notify key stakeholders (owners of the downstream applications) when there is a breaking change. Does this bring back memories of outages caused by some change made by an upstream application? Another benefit is identifying popular objects from orphaned objects. Discovering numerous orphaned topics and schemas that are not being used anymore can be very beneficial and avoid new applications from consuming stale streams of data that is not being maintained by anyone.
Kafka Challenge 3: Lack of Automation
The more you adopt any new technology across your enterprise, the more you need automation. Simple tasks such as documenting what topics and schemas you have on an Excel file is just not feasible anymore. That wiki page you were using to map key relationships has become stale and it’s an uphill battle every time to keep it updated. So, while both challenges above can be addressed by Event Portal for Kafka, do we really want to be responsible for keeping another tool up-to-date? We are all way too busy (ok, lazy) to do it. And manual intervention always introduces the risk of human error such as typos or missing something.
This is why Event Portal for Kafka comes with prebuilt integrations to make it easier to update it. Your developer can easily integrate Event Portal, using its API, into their pipeline so when they make any changes and commit them to git, those changes are reflected in Event Portal as well. The same developers can also go to Event Portal and download AsyncAPI spec files and use them for code generation so that they don’t need to waste their time writing boilerplate code. Instead, they can focus on adding business logic. These integrations lead to a well-integrated and up-to-date portal with information about your Kafka estate and reduced time to go to market for your developers.
There are many more integrations to increase your developers’ productivity such as with Slack so that your developers can share Kafka objects from Event Portal via Slack with their colleagues. There is another integration with Confluence so you can have wiki pages shared with other organizations with updated data from Event Portal.
Kafka Challenge 4: Lack of Depth
A developer at a small startup working in a team of a few developers won’t worry about versioning, but a large Fortune 500 company with thousands of developers certainly does. With time, as you roll out new iterations of applications, topics, and schemas, it becomes very challenging to keep track of the changes that are being made, who is making them, and why are they being made.
I talked above about lack of relationships and how a small change made by an upstream application to a topic can cause an outage downstream. As soon as the outage occurs, stakeholders want to know what caused the issue, who caused it, and how it can be avoided in future.
Event Portal stores objects in multi-dimensions with versioning and life-cycle management. This means that objects in Event Portal are stored with multiple versions. Every time a change is made, it can be applied to an existing version, or a new version can be created for auditing. Additional information such as who made the change, when was the change made, and why was the change made can also be provided. As companies continue to grow, and more and more changes are made over time, having support for versions gives you immense insight into how an object such as a topic or schema has evolved over time (and why).
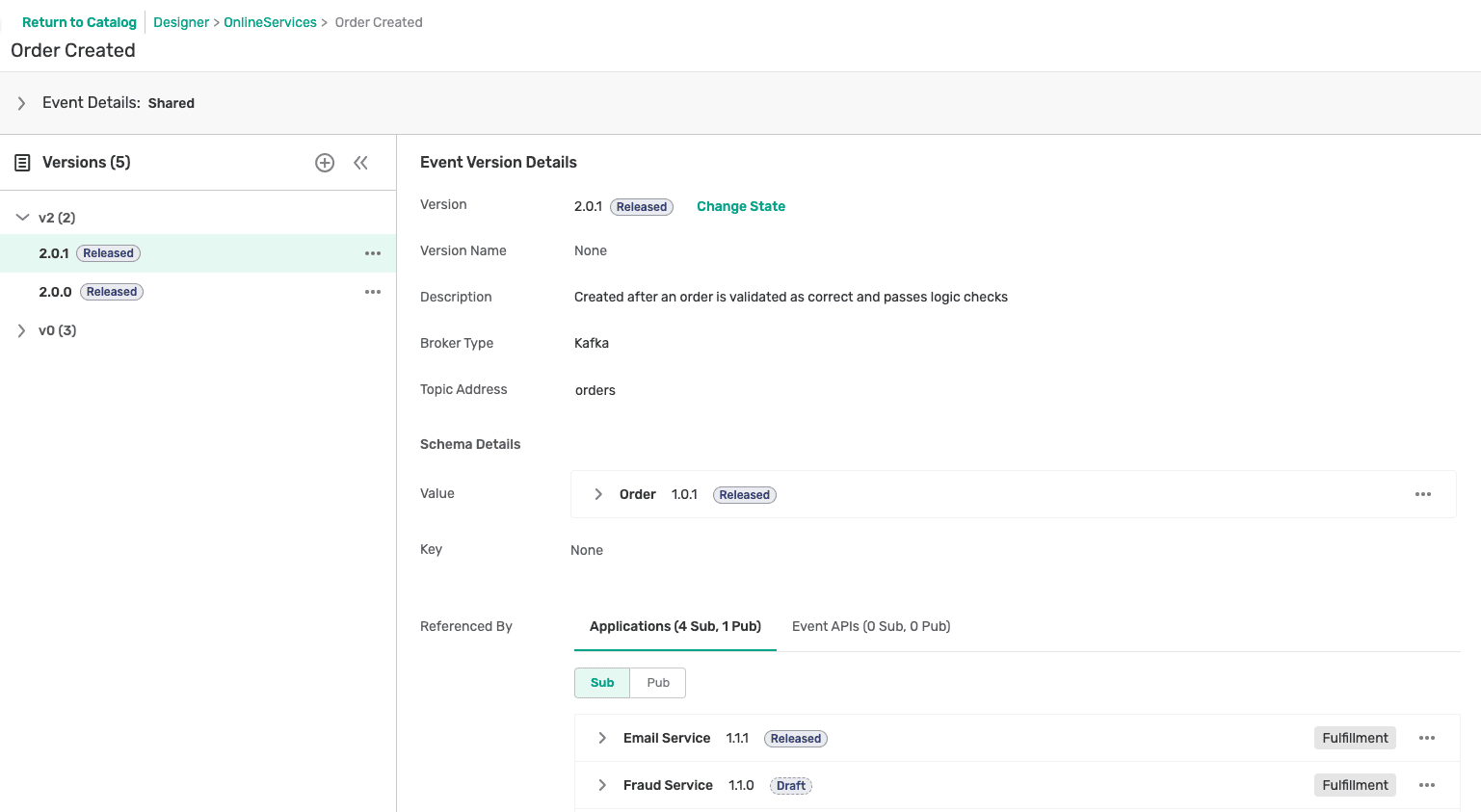
Additionally, an object might not live forever. Objects are created, tested, released, and finally deprecated. These stages of their existence are important to document and broadcast to consuming applications, so they do not make the mistake of consuming from a topic that has been deprecated. What business impact does this have? First, versioning provides you with another depth of insight into the objects that reside on your Kafka clusters. It allows you to understand the root cause of an outage faster by inspecting how an object has changed over time with additional information such as who made the change and more importantly, why that change was made. Finally, having support for lifecycle management prevents your application from consuming stale data which can possibly have business impact.
Conclusion
Kafka has seen wide adoption across companies of different sizes and as its adoption grows with the company, many challenges also come to light. These challenges are lack of insight into what objects existing in a company’s Kafka estate, how these objects relate to each other, how to keep these objects up-to-date without manual intervention, and how to provide versioning and life-cycle management for them over time. Event Portal for Kafka gives you all of that, so if these challenges resonate with you, reach out so we can talk about how Event Portal for Kafka’s discovery agent can quickly analyze your Kafka estate so you can see how things are going, if there is anything you can do to address the challenges mentioned above.
The post The 4 Key Challenges You’ll Face as Your Kafka Estate Grows appeared first on Solace.