How the PubSub+ Connector for Kafka Enables Fine-Grained Filtering, Protocol Conversion, and Scalable Delivery
Kafka is often used to aggregate massive amounts of log data and stream it to

Over the last few years Apache Kafka has taken the world of analytics by storm, because it’s very good at its intended purpose of aggregating massive amounts of log data and streaming it to analytics engines and big data repositories. This popularity has led many developers to also use Kafka for operational use cases which have very different characteristics, and for which other tools are better suited.
This is the first in a series of four blog posts in which I’ll explain the ways in which an advanced event broker, specifically PubSub+, is better for use cases that involve the systems that run your business. My goal is not to dissuade you from using Kafka for the analytics uses cases it was designed for, but to help you understand the ways in which PubSub+ is a better fit for operational use cases that require the flexible, robust and secure distribution of events across cloud, on-premises and IoT environments.
In most event-driven systems, you need to filter event streams so consumers aren’t overwhelmed with the proverbial “firehose of data,” and in situations where you’re acting on events, not just analyzing them, the order in which events are sent and received is very important.
For example, in an online store where orders transition in positive states from NEW to UPDATED, and on to RESERVED, PAID, and SHIPPED, and could also transition to negative states such as CANCELLED, DELAYED etc., each state change produces an event, and the order in which an application receives these events is critical.
Unfortunately, while Kafka supports both the filtration of events and the preservation of order, you can’t do both simultaneously.
Each event published to a Kafka broker is placed into a specific topic/partition. Temporal order between events published to different topics/partitions is lost. A consumer receiving events from multiple topic/partitions can receive events in mixed order, even if the events were initially published by a single producer in order. To ensure events are received in published order they must all be published to the same topic/partition, and there is no filtering inside a partition. That means if you put all events into one partition to preserve temporal order, applications can’t filter them to receive only those they want, and must receive all of them. Reducing the Kafka broker deployment to a single event stream is not typically done. Typically, a given Kafka producer publishes events to many different Kafka brokers and consumers consume from many Kafka brokers depending on the topic/partitions.
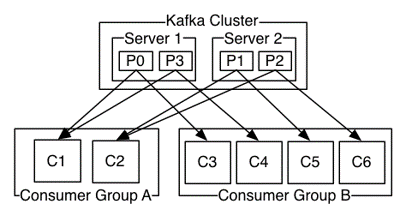
So with Kafka, your options are to:
On the other hand, events published to a Solace event broker are naturally processed, in order, in a single event stream per publisher; then a subset is delivered to consumers based on subscription filters. So all events from a producer across all topics are delivered, in the published order, to the subscribed consumers. That means you can publish events to topics that describe the events, applications subscribe to desired events, and the broker maintains order across topics.
Here is a great blog that describes the difference, and a video.
Kafka producers publish to a topic and key. The topic is a feed name of events as described here, and the “key” is hashed across available partitions while the event is written into the broker file system in the location of a single partition.
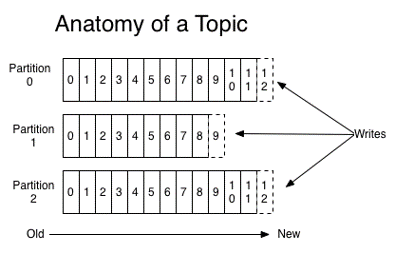
Consumers subscribe to a topic and read from the partitions. The events the consumer will receive are based on which topics they subscribe to. The partitions are not used to filter events, just to provide file locations to read from. A consumer consuming from a partition will receive all events in the partition un-filtered and they’ll need to make their own determination whether to process the event or discard.
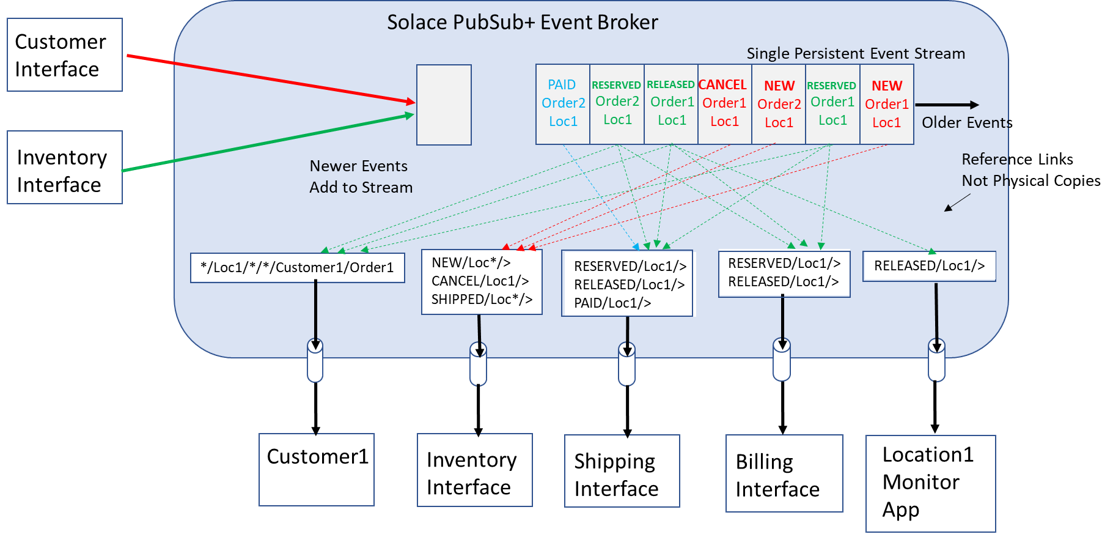
With PubSub+, producers publish events to a hierarchical topic that describes the event, and each publisher’s events are processed as a single, ordered event stream for all topics it publishes to. PubSub+ processes multiple per-publisher streams in parallel for performance and scale. In the diagram below you can see the Producer appending to the head of the event stream on the right, and consumers attracting the desired messages from the event stream.
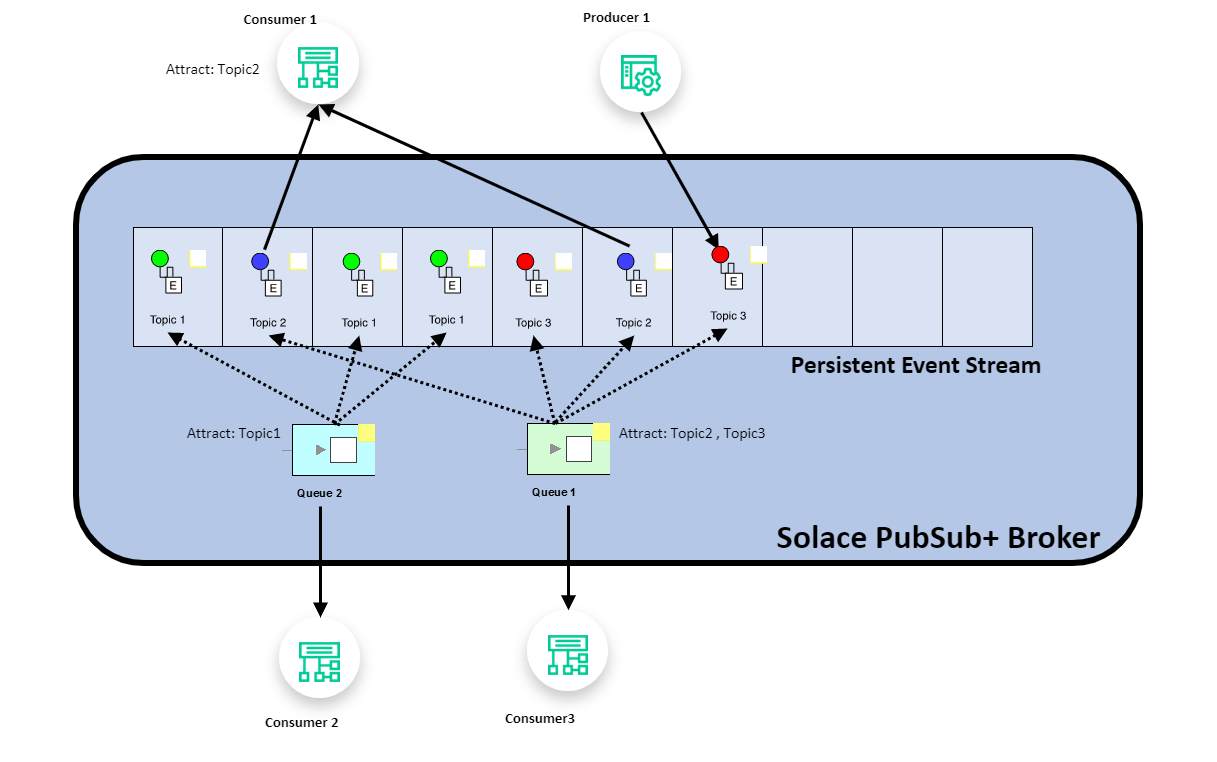
Consumers add subscriptions that describe the events they wish to consume. These events are delivered to the consumer in the order they were published.
I’ll illustrate my point with an example based on an online store that sells tens of thousands of items with thousands of SKUs and UPCs. Let’s say a development team has access to a raw feed of product order events that provides real-time information about purchases including product category, quantity, UPC, location, customerId, purchaseId, price, etc.
A developer has been tasked with giving a diverse set of downstream applications access to all events related to product purchases in real time. Let’s say that includes event types representing statuses such as new, reserved, paid and shipped.
An initial simplified event-driven design might look like this:
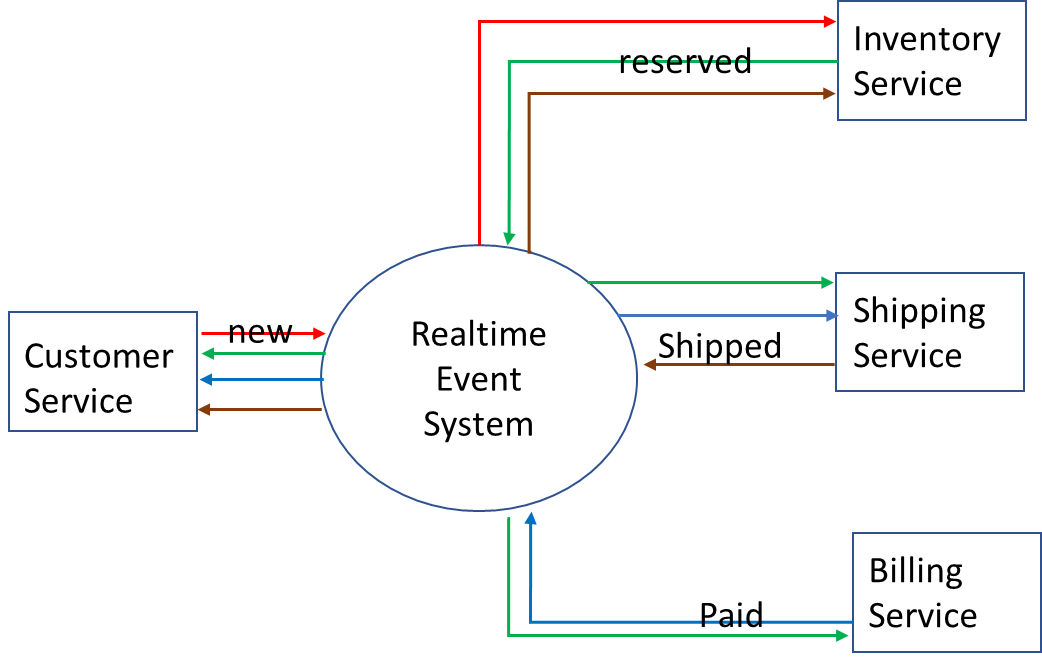
The customer injects a new order that includes region, product category, upc, quantity, customerId, and purchaseId, and registers to receive all events related to purchaseId.
The inventory service that is responsible for the region and product category receives the event and checks inventory. It will ideally emit a reserved event, unless there’s no inventory, in which case it will emit an OutOfStock event.
Let’s say it’s in stock, so the customer will be notified that the product is in stock and their order is reserved. At the same time, the billing service will receive the same information and start the billing process. Once billing confirms that payment has been made, the billing service will send a paid event to the shipping service so it can kick off the shipping process.
The life of the order would move from:
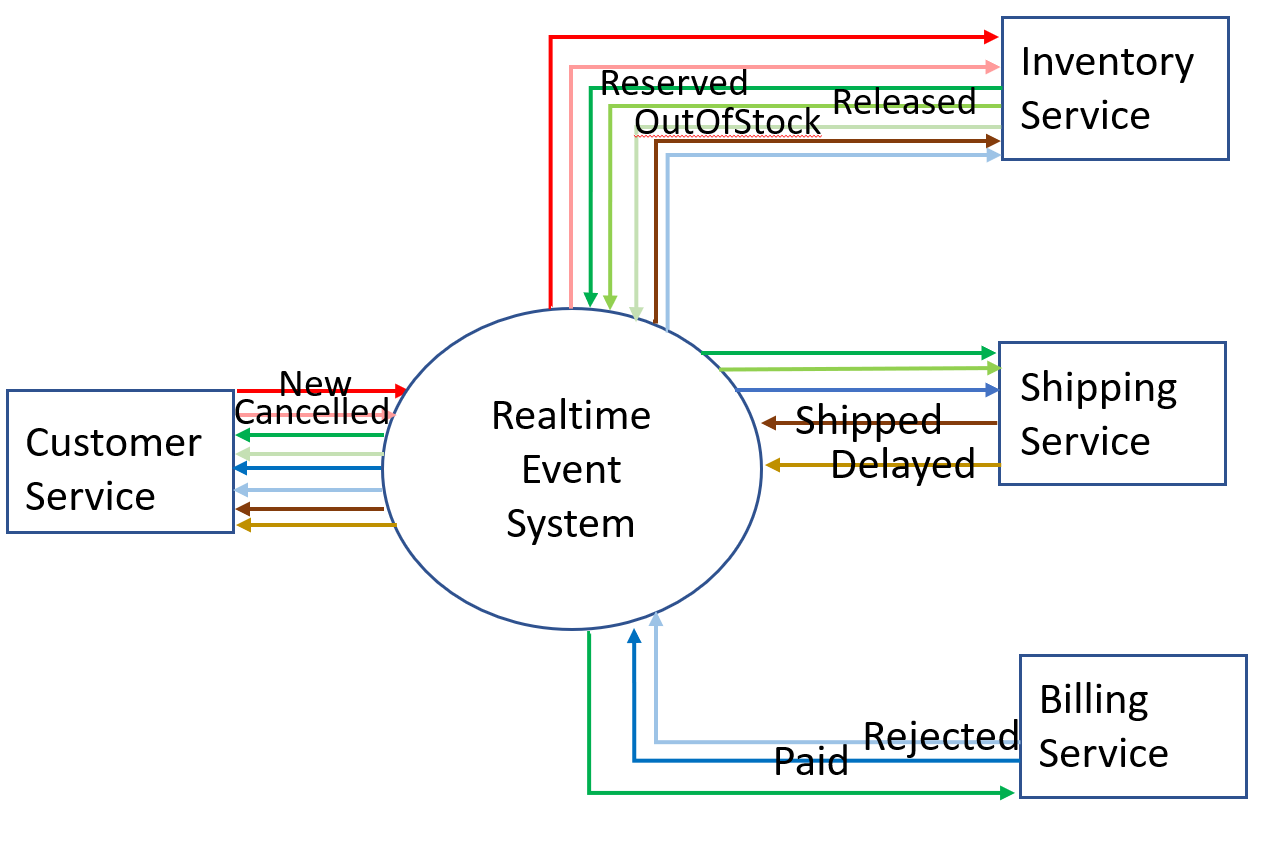
From the diagram above you can see that not all events from a given producer need to go to all consumers, but that some consumers do require multiple event types. For example, Customer, Shipping, and Billing services need to receive RESERVED events from the Inventory service, but only Customer service needs to receive OutOfStock, and only Shipping service needs to receive RELEASED.
If order is not preserved between these events, application logic becomes way more complex and will require additional code and testing, which increases the likelihood of defects. For example, what happens if…
And who knows what relationships will be assumed or required by future applications!
In contrast, if the event distribution system maintains the original order, you can keep applications lean and mean, easier to develop, maintain and modify.
First, you have two decisions to make: 1) what are the topics and 2) what are the keys.
For keys, the obvious options are the productId or the orderId. Selecting orderId would give a large number of keys which is generally good for event distribution when mapped to partition.
For topics, the options are one topic per event type, (e.g. NEW, CANCELLED), one topic per originating service type (e.g. Inventory, Shipping), or one topic per domain, something like ORDERS.
This would allow consumers to subscribe to the events they are designed to receive, and only receive these events. For example, from the Billing service the Inventory service would listen to REJECTED events, which might go down the path of releasing the inventory back to available stock, while the shipping would listen to PAID to ship the inventory. While still other services will have a broader set of subscriptions.
This option provides the best level of filtering but does have the significant issue of no order between events for a given producer. For example, the Inventory application could receive a CANCELLED event before NEW for a given order, or even concurrently in a distributed service. This means the application now must be stateful and track the state of each orderId so that it can re-order the events or process them differently. In highly scaled applications where the events are passed to stateless workers, this responsibility of reordering can have significant implications on application design, complexity and maintainability – typically resulting in increased development costs and decreased quality.
This would allow first-level of filtering and allow all events for an orderId sent from a service to be received in order. For example, if the Customer service sends events to topic CUSTOMER, some of which are NEW and some are CANCELLED, this seems to work. The Inventory service subscribes to CUSTOMER and receives the events it needs in order.
But what about the other services that send different events needed by different downstream services? For example, Billing sends events consumed by the Customer, Shipping and Inventory services, but the Shipping service and Inventory service only require a subset of the events: REJECTED for Inventory and PAID for Shipping. This means these services must do secondary filtering and discard events they are not interested in. This send-and-discard pattern means wasted resources on the broker, network and clients. It can also become a scalability issue and, in some use cases, this is not allowed due to security requirements.
This is more of a broadcast solution where events are broadcast to services to ensure order but with no filtering at all by the broker. Reading this blog from the Confluent CTO organization would lead you to believe this is about the best you could achieve. In this blog there is a mix of one topic per service type “Inventory” and one topic per domain, “Orders.” There are services that read from “Orders” topic and publish to “Orders” to record the transition of the order from one state to another, analogous to how a database commit log would record the various database transaction updates. This strategy maintains the temporal order of the events BUT all filtering is done in the application. It is therefore the responsibility of the application to read from a broadcast event stream and do all filtering.
Though fairly efficient on the Kafka broker, this approach is highly inefficient on every other component; network, application server CPU and possibly disk and memory and, again, may not be allowed in some cases due to security policy. It is difficult to predict which data is required in order for future use cases. Relying on this type of broadcast without filtering has the potential of complicating expansion of the use case with new re-use of events. Republishing events to a new topic for new reuses will cause events to no longer be ordered and adds additional scalability burden on the overall system. So, the new use cases may require consumption of the entire broadcast to receive the data it requires in order.
The first natural choice would be to have one topic per event type. This would allow consumers to subscribe to the events they are designed to receive, and only receive these events. For example, an application might want to only receive payment REJECTED events, which might go down the path of validating if the credit card on file has expired. Other applications will have a broader set of subscriptions. This provides the best level of filtering and maintains order between events for a given producer. There is no requirement for applications to reorder so they can statelessly scale, and no requirement to receive and discard events thereby preserving network and application host resources to perform real tasks.
Below we can see that services like Inventory need to subscribe to success and negative subscriptions to event topics like NEW and CANCEL and emit events to both success and negative topics like RESERVED and RELEASED. To simplify application design, it is important that it only receives a CANCEL event for orders that it already has a NEW event for. This removes the requirement to maintain state on each order it receives so that it can reconcile and reorder CANCEL and NEW events (because with PubSub+ it does not need to reorder). Similarly, the Shipping and Billing services are simplified by having order between RESERVED and RELEASED events. But there are also services like the Monitoring application that would only subscribe to negative events like RELEASED so that it filters out negative events and takes follow-up actions with the customer.
Having to choose between order and filtering could have different ramifications in different systems because different consumers need to have different filtered views of the same events and still require delivery in temporal order – this is very common.
For example, in an airline notification system for an airport they likely have the airline as the topic and the specific flight as the key in a Kafka-based system. This would work well until you need specific in-order information about two flights of different airlines, or between different flights of the same airline. The airport airline staff need to know about the flights for their airline, while the airport ground crew need to know about all flights. If out-of-order delivery of information is not valid for safety reasons, then the individual airline applications need to receive all info and filter. To solve this problem, you’d probably set up a primary stream with all airlines, and republish streams for specific airlines or other uses.
For some analytics applications where you are computing rolling averages or trends over time, order of events does not matter. But there are many use cases that do require both filtering and in-order delivery across topics – especially when taking action on each event. With Kafka, you either need to feed applications more data than they need and make them filter down to what they need, or put in place data filtering applications to do that work and republish the events they need on to new topics. Both of these approaches reduce agility, increase complexity and decrease scalability.
With Solace, you can easily filter events and maintain order without adding logic to your applications or deploying dedicated data filtering applications.
In the next post of this series, I introduce the importance of flexible topics and subscriptions, and explain a few limitations or workarounds that Kafka imposes or requires around topics.
Why You Need to Look Beyond Kafka for Operational Use Cases, Part 2: The Importance of Flexible Event FilteringSolace event brokers perform event filtering on topic metadata as a continuous stream so you can have fine-grained topics without scalability implications.
“We will have many copies of the same data embedded in different services which, if they were writable, could lead to collisions and inconsistency. As this notion of ‘eventual consistency’ is often undesirable in business applications, one solution is to isolate consistency concerns (i.e. write operations) via the single writer principle. For example, the Orders Service would own how an Order evolves in time. Each downstream service then subscribes to the strongly ordered stream of events produced by this service, which they observe from their own temporal viewpoint.”
“Building a Microservices Ecosystem with Kafka Streams and KSQL.” Confluent Microservices Blog, March 13, 2020. https://www.confluent.io/blog/building-a-microservices-ecosystem-with-kafka-streams-and-ksql/



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.
By submitting this form, you agree to Solace’s privacy policy: solace.com/privacy-policy/